Index
- Dischi RAID
- [[#Dischi RAID#Dischi multipli|Dischi multipli]]
- Gerarchia
- [[#Gerarchia#RAID 0 (nonredundant)|RAID 0 (nonredundant)]]
- [[#Gerarchia#RAID 1 (mirrored)|RAID 1 (mirrored)]]
- [[#Gerarchia#RAID 2 (redundancy though Hamming code)|RAID 2 (redundancy though Hamming code)]]
- [[#Gerarchia#RAID 3 (bit-intervaled parity)|RAID 3 (bit-intervaled parity)]]
- [[#Gerarchia#RAID 4 (block-level parity)|RAID 4 (block-level parity)]]
- [[#Gerarchia#RAID 5 (block-level distributed parity)|RAID 5 (block-level distributed parity)]]
- [[#Gerarchia#RAID 6 (dual redundancy)|RAID 6 (dual redundancy)]]
- [[#Gerarchia#Riassunto|Riassunto]]
Dischi RAID
RAID è l’acronimo di Redundant Arrays of Indipendent Disks. In alcuni casi, si hanno a disposizione più dischi fisici ed è possibile trattarli separatamente (es. Windows li mostrerebbe esplicitamente come dischi diversi, in Linux si potrebbe dire che alcune directory sono in un disco altre su un altro) oppure si possono considerare più dischi fisici come un unico disco
Dischi multipli
In Linux, il trattare diversi dischi separatamente è chiamato Linux LVM (Logical Volume Manager). Permette di avere alcuni files/directory sono memorizzati su un disco, altri si un altro e a farlo ci pensa direttamente il kernel (l’utente può non occuparsi di decidere dove salvare i file). Viene fatto dall’SO in quanto, se gestita dall’utente potrebbe succedere che una directory cresca fino a riempire il relativo disco, mentre l’altra resta vuota.
L’LVM va bene per pochi dischi, ed in generale se non si è interessati alla ridondanza (un dato è memorizzato uguale su più dispositivi). Se infatti fosse presente la ridondanza, nel caso di rottura di un disco, sarebbe possibile comunque recuperare il dato dall’altro disco (ovviamente modifiche al file su un disco vanno propagate anche all’altro/i disco/dischi)
A risolvere questo problema vi è il RAID, utile non solo per la ridondanza ma anche per velocizzare alcune operazioni
Info
Esistono device composti da più dischi fisici gestiti da un RAID direttamente a livello di dispositivo (il SO fa solo read e write, ci pensa il dispositivo stesso a gestire internamente il RAID). Il RAID che studiamo noi è frutto di una collaborazione tra hardware e software
Gerarchia
RAID 0 (nonredundant)
Qui i dischi sono divisi in strip ed ogni strip contiene un certo numero di settori. Un insieme di strips sui vari dischi (una riga) si chiama stripe
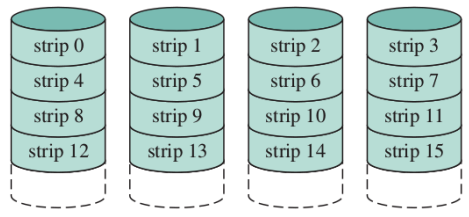
L’unico scopo del RAID 0 è la parallelizzazione, infatti uno stesso file viene diviso sull’intera stripe (sui vari dischi). Poiché non c’è ridodndanza, il mio file system è dato dall’unione di tutti i quanti i dischi
RAID 1 (mirrored)
Questo è uguale al RAID 0, ma duplicando ogni dato. Dunque si hanno , ma la capacità di memorizzazione è quella di dischi
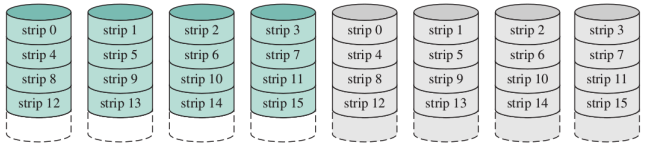
Quindi se si rompe un disco, recupero sicuramente i dati, ma se se ne rompono due dipende da quali si sono rotti
RAID 2 (redundancy though Hamming code)
Non viene usato Qui la ridondanza non viene fatta attraverso una semplice copia, ma tramite opportuni codici. Serve per proteggersi nei casi (rari) in cui gli errori non sono il fallimento di un intero disco, ma magari il flip di quale singolo bit (es. Hamming permette di correggere errori su singoli bit e rilevare errori su 2 bit)
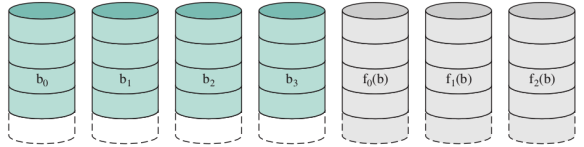
Non più dischi di overhead, ma tanti quanti servono per memorizzare il codice di Hamming che è proporzionale al logaritmo della capacità dei dischi
RAID 3 (bit-intervaled parity)
Non viene usato Qui viene usato un solo disco di overhead. Viene infatti memorizzato, per ogni bit, la parità dei bit che hanno la stessa posizione (se numero pari di 1 memorizza 1 altrimenti 0). Nonostante la sua semplicità resta possibile recuperare i dati quando fallisce un unico disco; però è irrecuperabile se fallisce il disco di parità
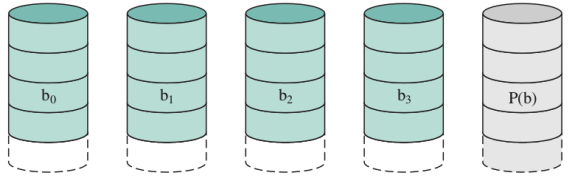
RAID 4 (block-level parity)
Non viene usato Come il RAID 3, ma ogni strip è un “blocco”, potenzialmente grande. Recuperabile in caso di fallimento di un unico disco. Migliora il parallelismo rispetto al RAID 3, ma è più complicato gestire piccole strutture
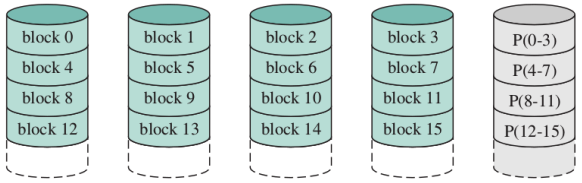
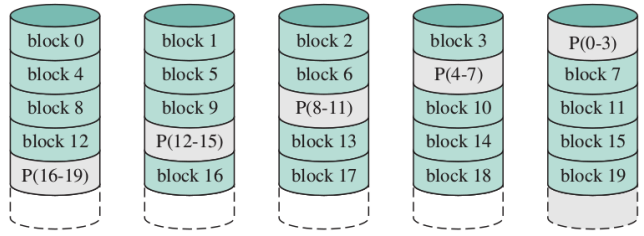
RAID 5 (block-level distributed parity)
Come il RAID 4, ma le informazioni di parità non sono tutte su un unico disco, evitando il collo di bottiglia del disco di parità (non esiste un disco “privilegiato”)
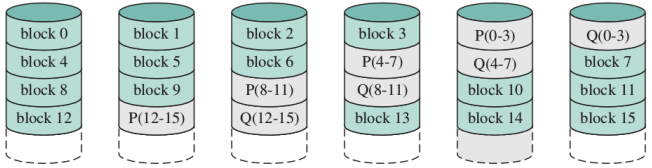
RAID 6 (dual redundancy)
Come RAID 5, ma con 2 dischi di parità indipendenti. Permette di recuperare anche 2 fallimenti di disco, ma con una penalità del (a livello di efficienza) in più rispetto dal RAID 5 per le operazioni di scrittura. Per le operazioni di lettura, RAID 5 e RAID 6 si equivalgono
Riassunto
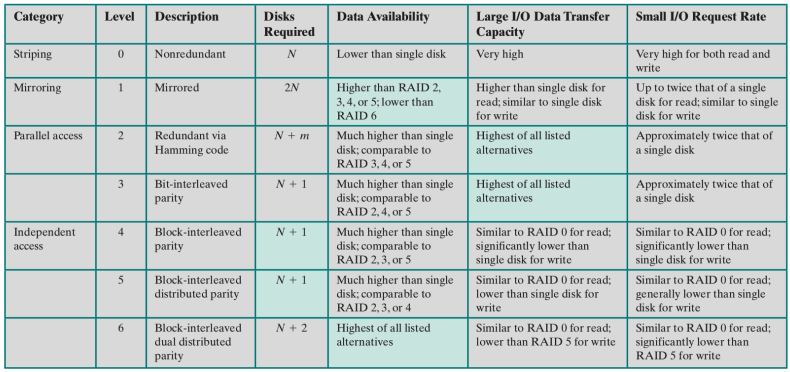
Parallel access → se faccio un’operazione sul RAID, tutti i dischi effettuano in sincrono quell’operazione Indipendent → un’operazione sul RAID è un’operazione su un sottoinsieme dei suoi dischi (permette il completamento in parallelo di richieste I/O distinte) Data availability → capacità di recupero in caso di fallimento Small I/O request rate → velocità nel rispondere a piccole richieste di I/O